An introduction to Artificial Intelligence & Data
Artificial Intelligence, in short AI, is a very broad term with a lot of associations. It is often considered a “black box”, because we are not always how decisions are made by AI. For this blog, I’ll focus on AI from a data science & statistics perspective.
Let’s have a look at our dataset below on coffee & tea.
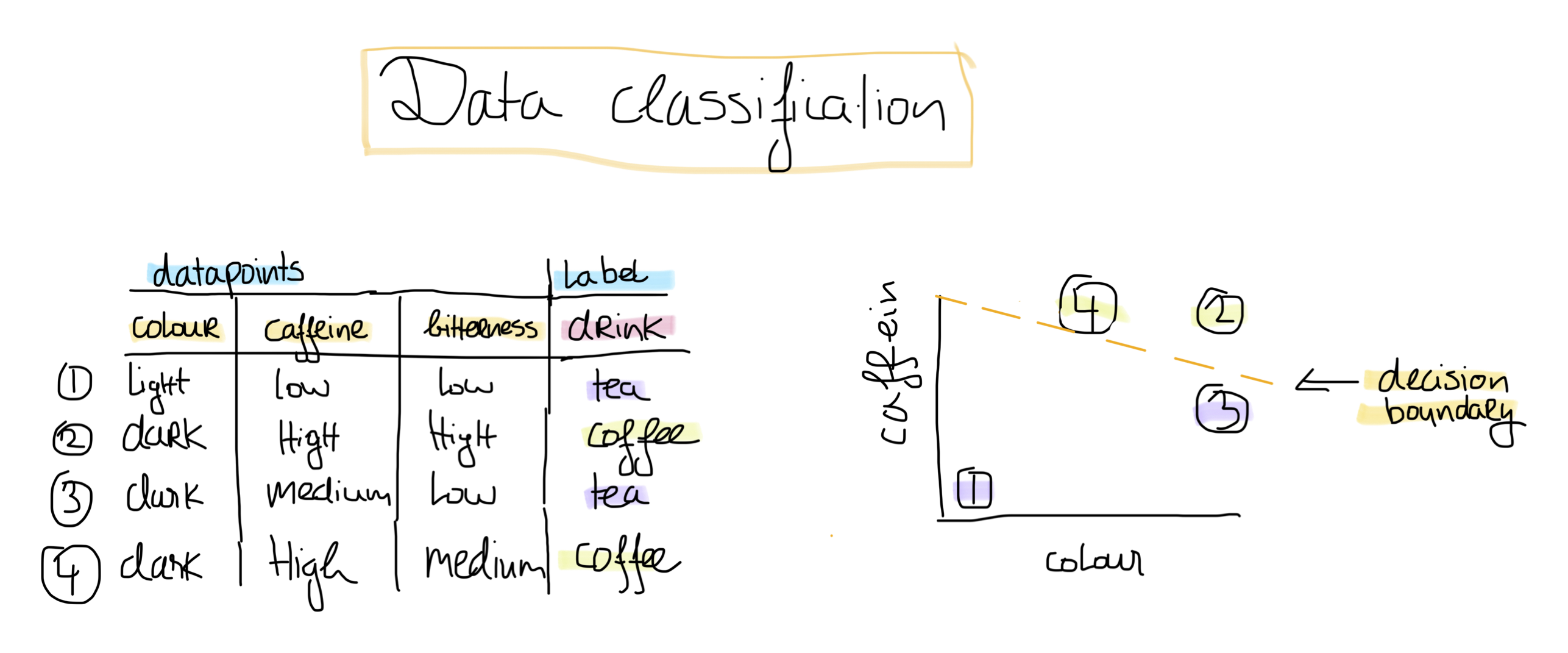
Each row in our dataset is considered a datapoint. This is one instance of either coffee or tea. A datapoint can have multiple features. These are characteristics used to describe the datapoint. In our example, the features are the colour, amount of caffeine and the bitterness level. Based on these features, we can estimate if our drink is either coffee or tea, which is called the label. In the image above, a decision boundary is visualised based on our current dataset using two features.
Keywords
- Datapoint - a single information point in a dataset
- Dataset - a collection of datapoints
- Decision boundary - the (hyper)surface in machine learning that seperates classes
- Features - characteristics used to describe a certain datapoint
- Label - the classification of a certain datapoint into a group